

Hầu hết những ai mới học Power BI đều từng trải qua cảm giác “thành công” sau khi làm xong dashboard đầu tiên. Chỉ vài cú click: Get Data → Transform → Load → Vẽ biểu đồ, là đã có ngay dashboard màu sắc, số liệu đúng, chạy mượt. Nhưng rồi khi bước vào môi trường thật, mọi thứ bỗng khác hẳn. Cũng là thao tác đó, nhưng query chạy mãi không xong, refresh bị lỗi, KPI không khớp ERP, hoặc báo cáo mất cả đêm mới load được. Lúc đó bạn mới nhận ra: “À, ở lớp mình học Power BI — còn ở công ty, mình đang làm Business Intelligence.”
Sự khác biệt nằm ở chỗ: trong lớp, dữ liệu được “làm sẵn” để học viên có thể tập trung vào công cụ. Còn ở công ty, dữ liệu thật lại là một mê cung: không đồng nhất, chứa lỗi, trễ nhịp, và bị ảnh hưởng bởi rất nhiều yếu tố vận hành. Dashboard không chỉ cần đẹp mà còn phải đúng, nhanh, ổn định, và có thể bảo trì. Đó là lúc bạn bắt đầu hiểu rằng Power BI không chỉ là công cụ vẽ biểu đồ, mà là một phần trong hệ thống dữ liệu lớn hơn — nơi mỗi chi tiết nhỏ (refresh, model, gateway, RLS…) đều có thể khiến cả hệ thống “ngừng thở” nếu làm sai.
Học Power BI giống như học cách lái xe trên sa hình, nhưng đi làm là chạy giữa cao tốc, đông xe và nhiều luật. Vấn đề không còn là “biết chạy”, mà là “biết sống sót và về đích an toàn”.
Dữ liệu thực tế: Nguồn, lỗi, snapshot, incremental refresh
Trong lớp học, bạn nhận được file Excel vài nghìn dòng, không lỗi, định dạng chuẩn. Nhưng trong thực tế, dữ liệu của doanh nghiệp thường đến từ 5–10 hệ thống khác nhau: ERP lưu đơn hàng, CRM lưu khách hàng, OMS lưu vận hành, WMS lưu kho, marketing lưu chi phí quảng cáo, kế toán lưu dòng tiền, và tất nhiên không thể thiếu hàng tá file Excel nội bộ. Mỗi nguồn một cấu trúc, một cách đặt tên, một quy tắc ghi nhận thời gian khác nhau. Bạn có thể mất hàng ngày chỉ để hiểu dữ liệu mình đang nhìn là gì.

Điểm khác biệt lớn nhất giữa “học” và “làm” nằm ở khái niệm dữ liệu thật không bao giờ sạch. Không có chuyện dữ liệu hoàn hảo — chỉ có dữ liệu đủ tin cậy để dùng. Khi đó, công việc của người làm BI không phải “làm sạch tất cả”, mà là xác định đâu là lỗi chấp nhận được, đâu là lỗi phải xử lý gốc rễ. Ví dụ: cột “Doanh thu” bị lệch 1–2 đồng do làm tròn thì có thể bỏ qua, nhưng lệch vài triệu do trùng đơn hoặc mapping sai thì phải điều tra.
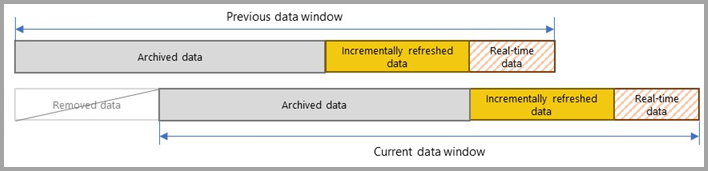
Vì dữ liệu thay đổi liên tục theo thời gian, doanh nghiệp cần khái niệm snapshot – tức là lưu lại “ảnh chụp” dữ liệu tại từng thời điểm. Nhờ đó, bạn có thể so sánh tồn kho tuần trước và tuần này, hoặc xem doanh thu từng tháng mà không bị lệch do cập nhật muộn. Khi chưa hiểu snapshot, nhiều bạn mới đi làm thường lấy toàn bộ dữ liệu “hiện tại” để tính KPI lịch sử — dẫn đến kết quả sai hoàn toàn.
Cùng với snapshot là incremental refresh, một tính năng “cứu rỗi” trong Power BI. Ở lớp, bạn có thể refresh toàn bộ dataset vài nghìn dòng trong vài giây, nhưng ở công ty, dữ liệu vài trăm triệu dòng thì refresh full mỗi ngày là điều không tưởng. Incremental refresh cho phép chỉ làm mới phần dữ liệu mới (ví dụ 7 hoặc 30 ngày gần nhất), còn phần cũ giữ nguyên. Muốn làm được điều đó, bạn phải hiểu query folding (Power BI có đẩy được logic về database hay không), RangeStart/RangeEnd, và cách chia partition hợp lý.
Một vấn đề khác là hiệu suất. Nhiều bạn mới đi làm ngạc nhiên khi thấy cùng một bảng mà load trong Power BI mất hàng phút. Lý do là vì chưa tối ưu nguồn dữ liệu. Ở lớp, bạn thường load file tĩnh từ máy; còn ở công ty, dữ liệu đến từ server SQL, API, hoặc SharePoint — mỗi nơi có độ trễ riêng. Chỉ cần một phép merge sai chỗ hoặc một cột tính toán không được đẩy về server là có thể khiến toàn bộ quá trình refresh “đơ” hàng tiếng.
Thực tế, 70% thời gian của BI developer không nằm ở việc vẽ dashboard, mà là hiểu và làm chủ dữ liệu đầu vào. Bạn phải học cách viết query, kiểm tra chênh lệch, tối ưu cấu trúc bảng, và phối hợp với IT để thiết lập dataflow hợp lý. Còn dashboard chỉ là phần thưởng sau cùng – thứ người dùng nhìn thấy sau khi bạn đã “chiến đấu” với dữ liệu cả tuần.
Mô hình dữ liệu: Từ flat table đến star schema
Ở lớp, bài tập Power BI thường bắt đầu với một bảng “flat”: mỗi dòng là một đơn hàng, đầy đủ thông tin từ mã khách hàng, sản phẩm, đến khu vực, giá trị, ngày mua. Tất cả nằm trong một bảng duy nhất. Nhìn rất dễ hiểu, dễ thao tác, nhưng đó là mô hình chỉ phù hợp để học, không thể dùng khi dữ liệu thật tăng lên gấp trăm, gấp nghìn lần.
Trong thực tế, các doanh nghiệp tổ chức dữ liệu theo mô hình
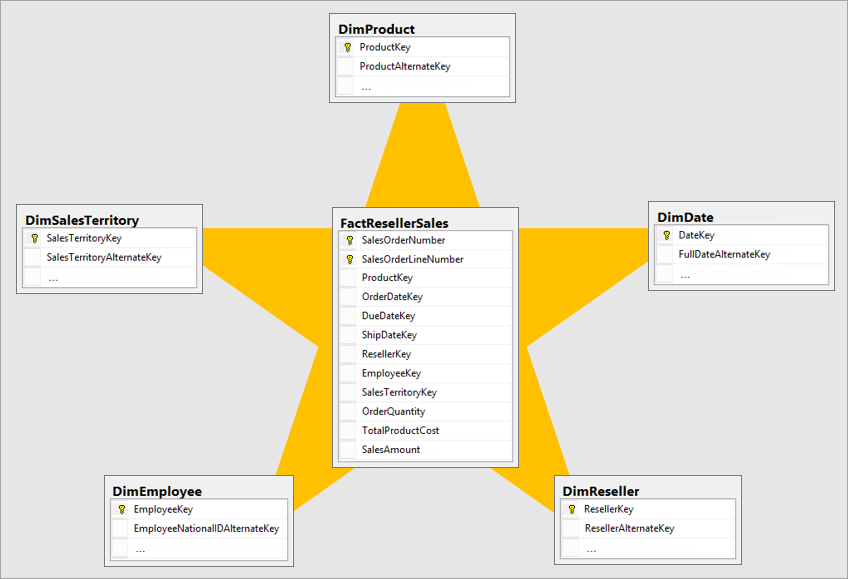
Star Schema (mô hình ngôi sao). Ở trung tâm là
Fact Table nơi chứa các giao dịch: đơn hàng, xuất nhập kho,
doanh thu, chi phí, v.v. Xung quanh là các Dimension Table những
bảng mô tả như Sản phẩm, Khách hàng, Thời gian, Nhân viên, Khu vực. Mỗi bảng
Dimension chỉ chứa thông tin mô tả và khoá định danh (product_id, customer_id, date_key) để kết
nối với Fact.
Lúc đầu, nhiều người cảm thấy mô hình này “rườm rà”, nhưng càng làm thật bạn càng thấy nó là xương sống của một hệ thống BI bền vững. Bởi vì:
- Tốc độ truy vấn nhanh hơn – Thay vì join hàng trăm cột trong một bảng lớn, Power BI chỉ cần join Fact với vài Dimension theo key, giảm đáng kể dung lượng bộ nhớ.
- Dễ bảo trì – Khi cần thêm thông tin sản phẩm mới, bạn chỉ cập nhật bảng Dimension; không cần chạm vào Fact.
-
Đảm bảo tính nhất quán KPI – Mọi chỉ tiêu đều được tính
từ cùng một nguồn, cùng công thức. Ví dụ: doanh thu =
SUM(Fact_Sales[amount]), chiết khấu =SUM(Fact_Discount[value]). Không còn chuyện mỗi dashboard tự định nghĩa riêng. - Mở rộng dễ dàng – Khi doanh nghiệp mở thêm ngành hàng, chi nhánh, hay hệ thống mới, chỉ cần thêm Dimension hoặc Fact tương ứng, không cần làm lại toàn bộ model.
Điều thú vị là, mô hình ngôi sao không chỉ là “kỹ thuật”, mà còn thể hiện tư duy tổ chức dữ liệu theo ngữ cảnh kinh doanh. Một bảng Fact là nơi lưu “hành động” (ví dụ: mua hàng, đặt hàng, trả hàng), còn Dimension là “ai, cái gì, ở đâu, khi nào”. Khi đã hiểu điều này, bạn không chỉ đang làm BI, mà đang “mô hình hóa doanh nghiệp bằng dữ liệu”.
Tuy nhiên, Star Schema không phải lúc nào cũng là lựa chọn nhanh nhất. Có một tình huống thực tế mà team BI của tôi từng gặp: dữ liệu bán hàng chỉ khoảng 400.000 dòng, kết nối trực tiếp từ Excel hoặc CSV — nếu tách ra thành Fact và 5 bảng Dimension (Sản phẩm, Khách hàng, Nhân viên, Thời gian, Khu vực), Power BI phải join giữa nhiều bảng, tốn thêm thời gian xử lý quan hệ. Trong khi đó, nếu gộp tất cả thành một bảng phẳng (Flat Table), truy vấn lại chạy nhanh hơn gấp đôi, vì engine không cần dựng mối quan hệ.
Nguyên nhân là với dataset nhỏ, việc join và ánh xạ key tốn nhiều chi phí hơn lợi ích mang lại. Power BI chỉ phát huy sức mạnh mô hình hoá khi dữ liệu đạt quy mô hàng triệu dòng, hoặc khi cần dùng chung dataset cho nhiều báo cáo.
Bài học rút ra:
- Nếu dữ liệu nhỏ, tạm thời ổn định và chỉ phục vụ một dashboard → mô hình flat có thể hiệu quả hơn.
- Nếu dữ liệu lớn, nhiều bảng dùng chung, hoặc cần mở rộng, phân quyền, refresh tự động → mô hình star schema mới thực sự phát huy giá trị.
Một cách dễ hiểu: Flat table giúp bạn chạy nhanh, Star schema giúp bạn sống lâu. Ở lớp, bạn học để “chạy”, nhưng khi đi làm, bạn phải chọn cấu trúc sao cho hệ thống chạy ổn định lâu dài, dễ mở rộng và dễ bảo trì.

So với việc học trên bảng phẳng, mô hình ngôi sao dạy bạn tư duy hệ thống. Mỗi bảng, mỗi mối quan hệ đều có lý do tồn tại. Khi bạn hiểu cách dữ liệu được tổ chức, bạn không chỉ “biết dùng Power BI”, mà còn “biết thiết kế nền tảng BI”. Và đó chính là điểm phân biệt giữa một người làm báo cáo và một người xây dựng hệ thống dữ liệu.
Học Power BI, việc chuẩn bị nguồn dữ liệu là rất quan trọng
Ở lớp, bạn học Power BI như học vẽ – tạo nên những dashboard đẹp mắt từ dữ liệu có sẵn. Nhưng khi đi làm, Power BI trở thành công cụ kỹ thuật trong một quy trình phức tạp hơn nhiều: làm việc với dữ liệu thật, hiểu cách nó được sinh ra, làm sạch, lưu trữ, và mô hình hóa. Chỉ khi bước qua giai đoạn “biết vẽ” sang “biết xây”, bạn mới thật sự đang làm BI đúng nghĩa.




0 Nhận xét